
In the realm of modern data management, the concept of Data Lake Engineering has emerged as a pivotal approach for organizations to store, process, and analyze vast volumes of data. The crux lies in achieving stability while simultaneously striving for scalability in the data lake ecosystem. Let’s delve into the intricacies of maintaining stability and achieving scalability in the dynamic world of Data Lake Engineering.
Introduction
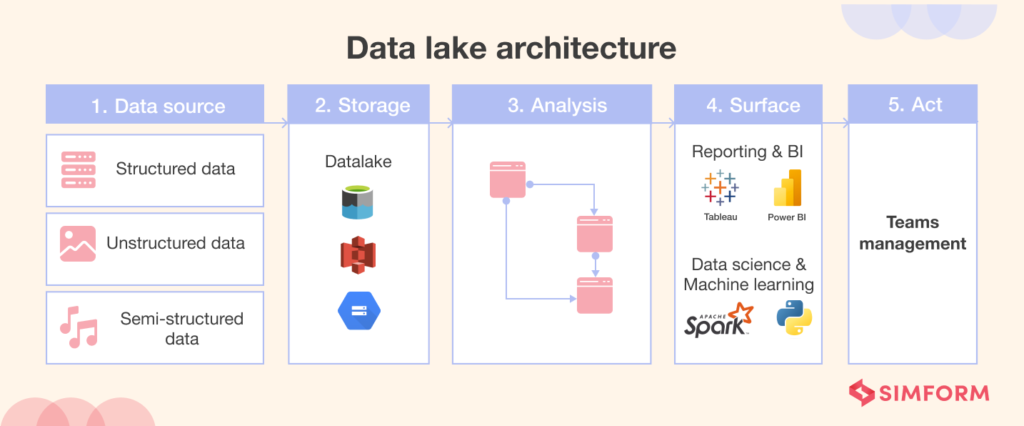
Definition of Data Lake Engineering
At its core, Data Lake Engineering involves the storage of structured and unstructured data in a centralized repository. This reservoir facilitates analytics, reporting, and other data-processing tasks. The term “engineering” emphasizes the structured design and management required for effective utilization.
Importance of Stability and Scalability
Stability ensures reliability in data processing, preventing disruptions that may hinder business operations. Simultaneously, scalability allows organizations to adapt and grow, accommodating increased data volumes and analytical demands.
Key Components of Data Lake Engineering
Understanding the foundational elements of Data Lake Engineering is crucial to achieving stability and scalability.
Storage Systems
Selecting appropriate storage systems is fundamental. Robust storage solutions ensure data integrity and accessibility, laying the groundwork for a stable data lake.
Data Ingestion Tools
Efficient data ingestion tools streamline the process of bringing data into the lake. Ensuring these tools can handle varying data volumes is essential for scalability.
Metadata Management
An organized metadata management system enhances stability by providing insights into the nature and context of stored data.
Challenges in Achieving Stability
Perplexities in Large-Scale Data Management
Dealing with vast amounts of data introduces complexities. Organizations must navigate through diverse data types, formats, and sources.
Burstiness in Data Flows
Data bursts, and sudden surges in data volume, pose challenges. Managing burstiness requires adaptive systems capable of handling peak loads.
Strategies for Maintaining Stability
Efficient Resource Allocation
Striking a balance in resource allocation prevents bottlenecks. Allocating resources dynamically based on workload optimizes stability.
Robust Data Validation Processes
Implementing rigorous data validation ensures the accuracy and consistency of the data lake, contributing to stability.
Monitoring and Alert Systems
Real-time monitoring and alert systems enable proactive identification and resolution of potential issues, maintaining stability.
Achieving Scalability in Data Lake Engineering
Horizontal Scaling
Horizontal scaling involves adding more hardware or nodes to distribute the load, allowing the data lake to scale seamlessly.
Optimizing Data Processing Workflows
Fine-tuning data processing workflows enhances efficiency, ensuring scalability without compromising stability.
Adaptive Infrastructure
Creating an adaptive infrastructure enables the data lake to adjust to varying workloads, supporting scalability.
The Role of Cloud Technologies
Cloud Storage Solutions
Leveraging cloud storage solutions provides a scalable and cost-effective way to manage and store data.
Serverless Architectures
Serverless architectures eliminate the need for managing infrastructure, allowing organizations to focus on scalability.
Case Studies of Successful Implementations
Company A: Overcoming Burstiness
By implementing adaptive infrastructure, Company A effectively managed burstiness, ensuring stability during peak data loads.
Company B: Scaling Data Lake for Business Growth
Company B strategically optimized data processing workflows, achieving scalability aligned with business growth.
Importance of Human Intervention
Data Governance and Compliance
Human intervention is critical for implementing robust data governance policies and ensuring compliance and stability.
Continuous Improvement
A culture of continuous improvement fosters adaptability, a key factor in achieving scalability.
Future Trends in Data Lake Engineering
AI-driven Data Management
Artificial Intelligence plays a pivotal role in automating data management tasks, paving the way for more scalable systems.
Edge Computing Integration
Integrating edge computing into data lake architecture enhances processing speed, contributing to scalability.
Conclusion
In conclusion, maintaining stability while achieving scalability in Data Lake Engineering requires a strategic and holistic approach. Organizations must focus on efficient resource utilization, robust validation processes, and the integration of adaptive technologies. Cloud solutions and human intervention play vital roles in navigating the challenges posed by large-scale data management. Embracing future trends ensures that data lakes remain dynamic, scalable, and resilient.
FAQs
- Q: How can organizations address burstiness in data flows?
- A: Implementing adaptive infrastructure and real-time monitoring systems helps organizations effectively manage burstiness.
- Q: Why is human intervention crucial in data lake engineering?
- A: Human intervention is essential for implementing robust data governance, ensuring compliance and stability.
- Q: What role does AI play in the future of data lake engineering?
- A: AI-driven data management automates tasks, contributing to more scalable and efficient data lakes.
- Q: How can organizations optimize data processing workflows for scalability?
- A: Fine-tuning data processing workflows enhances efficiency, supporting scalability without compromising stability.
- Q: What is the significance of continuous improvement in data lake engineering?
- A: A culture of continuous improvement fosters adaptability, a key factor in achieving scalability and long-term success.
